A long time ago, after I nearly got hit on the way to her house, a family friend told me that people always get loony (appropriate terminology) during full moons—be careful on the road when the moon is bright. A silly wives’ tale, I told myself. Certainly, there was nothing to back it up. The legitimacy of an idea like clinical lunacy had long been debunked. But then I encountered another erratic driver on the way home, and checked Google. Sure enough, it was a full moon that day. It’s not that I’ve ever been truly been convinced, but the idea has long eaten at me, mostly because in my experience it has nearly always turned out to be true.
A driver nearly runs me off the road? I check, and it’s a full moon that day. My friend gets slammed into at a red light? It happened on a full moon. And just a few months ago, I barely dodge the drunkest of drivers: it was a full moon. Even a handful of my most cynical friends have jumped on board the loony driver train.
It’s been years now, and I finally decided that I can’t let this gnaw at my brain any longer. So I did what any reasonable person would do with their first free weekend after graduating from undergrad: I collected data from the National Highway Traffic Safety Administration’s very robust Fatality Analysis Reporting System (FARS), prepared a gradient boosting tree model, and constructed a hypothesis test.
Setting things up
Since this method was assigned to the students to realize it was flawed from the start, I decided to create a grouped boxplot, Figure 1, to visualize the same data. I scaled age, education, and income levels to the same metric, \(n\), to reflect their rough distribution across different poll answers.
Code
# library(regplot)library(reshape2)library(tidyverse)library(tidymodels)library(plotly)library(haven)TEDS_2016 <-read_stata("https://github.com/datageneration/home/blob/master/DataProgramming/data/TEDS_2016.dta?raw=true")# opt. remove non-responses before relabellingTEDS_2016 <-filter(TEDS_2016, Tondu <8)TEDS_2016$Tondu <-factor(TEDS_2016$Tondu, levels=c(1,2,3,4,5,6,9), labels=c("Unification now", "Status quo, unif. in future", "Status quo, decide later", "Status quo forever", "Status quo, indep. in future", "Independence now", "No response"))newvars <-c("Tondu", "female", "DPP", "age", "income", "edu", "Taiwanese", "Econ_worse")TEDS_subs <- TEDS_2016[complete.cases(TEDS_2016[ , newvars]), ]# lm.fit=lm(Tondu~age+edu+income, data=TEDS_subs)# summary(lm.fit)# regplot(lm.fit)# thank you plotly for teaching me# -- learning how to use '%>%' from dplyr here# ditching the linear regression per the assignment# i think a boxplot model is much prettier for Tondu data# leaving linnmodel here for posterity's sake# _____________________________________________# lm_model1 <- linear_reg() %>% # set_engine('lm') %>% # set_mode('regression') %>%# fit(Tondu ~ age, data = TEDS_subs) # # y <- TEDS_subs$Tondu# x1 <-TEDS_subs$age# # x1_range <- seq(min(x1), max(x1), length.out = 100)# x1_range <- matrix(x1_range, nrow=100, ncol=1)# x1df <- data.frame(x1_range)# colnames(x1df) <- c('age')# # y1df <- lm_model1 %>% predict(x1df)# # colnames(y1df) <- c('Tondu')# xy1 <- data.frame(x1df, y1df) # # fig <- plot_ly(TEDS_subs, x = ~Tondu, y = ~age, type = 'scatter', alpha = 0.65, mode = 'markers', name = 'Age')# fig <- fig %>% add_trace(data = xy1, x = ~Tondu, y = ~age, name = 'Regression Fit', mode = 'lines', alpha = 1)# fig# Now we look at grouped boxplots# ________________________________# fig <- plot_ly(TEDS_subs, x = ~Tondu, y = ~age, type = "box")# fig# At this point I realized that displaying Tondu against different variables # wouldn't work because the y-axes would be different (possible but clunky)# Going to scale age, income, edu on same scale from 0, 10# If necessary using maximum absolute method (x/max(x))TEDS_subs['age'] <-apply(TEDS_subs['age'], 2, function(x) 10*x/max(x))TEDS_subs['edu'] <-apply(TEDS_subs['edu'], 2, function(x) 2*x)# I found no other way to go about this but to jankily# rip apart my existing df, pull "age" "edu" and "income"# individually, then force it all back together in a# single long-formTEDS_age <- TEDS_subs[c('age', 'Tondu')]TEDS_age <- TEDS_age %>%rename("n"="age") %>%mutate(type="Age")TEDS_edu <- TEDS_subs[c('edu', 'Tondu')]TEDS_edu <- TEDS_edu %>%rename("n"="edu") %>%mutate(type="Education")TEDS_income <- TEDS_subs[c('income', 'Tondu')]TEDS_income <- TEDS_income %>%rename("n"="income") %>%mutate(type="Income")TEDS_plot <-rbind(TEDS_age, TEDS_edu, TEDS_income)fig <-plot_ly(TEDS_plot, x =~Tondu, y =~n, color =~type, type ="box")fig <- fig %>%layout(boxmode ="group")fig
Figure 1: Tondu boxplot
3D visualization of data
Obviously, age, income level and education level are intricately related. Comparing them on one shared axis is inconclusive. A further analysis involving principal component analysis would give a much clearer picture on how each variable independently relates to the Tondu answers. Figure 2 is a 3D plot showing the responses we are observing.
Code
TEDS_2016 <-read_stata("https://github.com/datageneration/home/blob/master/DataProgramming/data/TEDS_2016.dta?raw=true")# opt. remove non-responses before relabellingTEDS_2016 <-filter(TEDS_2016, Tondu <8)TEDS_2016$Tondu <-factor(TEDS_2016$Tondu, levels=c(1,2,3,4,5,6,9), labels=c("Unification now", "Status quo, unif. in future", "Status quo, decide later", "Status quo forever", "Status quo, indep. in future", "Independence now", "No response"))newvars <-c("Tondu", "female", "DPP", "age", "income", "edu", "Taiwanese", "Econ_worse")TEDS_subs <- TEDS_2016[complete.cases(TEDS_2016[ , newvars]), ]fig <-plot_ly(TEDS_subs, x =~age, y =~income, z =~edu, color =~Tondu) %>%add_markers(size =12)fig
Figure 2: Tondu 3D
PCA
To accomplish the PCA, I assigned Tondu answers on their own scale, \(t\), where \(t=1\) indicates strong reunification sentiment and \(t=5\) indicates strong independence sentiment. Note that while these two ideas are opposed, further analysis should consider \(t=3\) “pro-status quo” to be strong and oppositional in its own right.
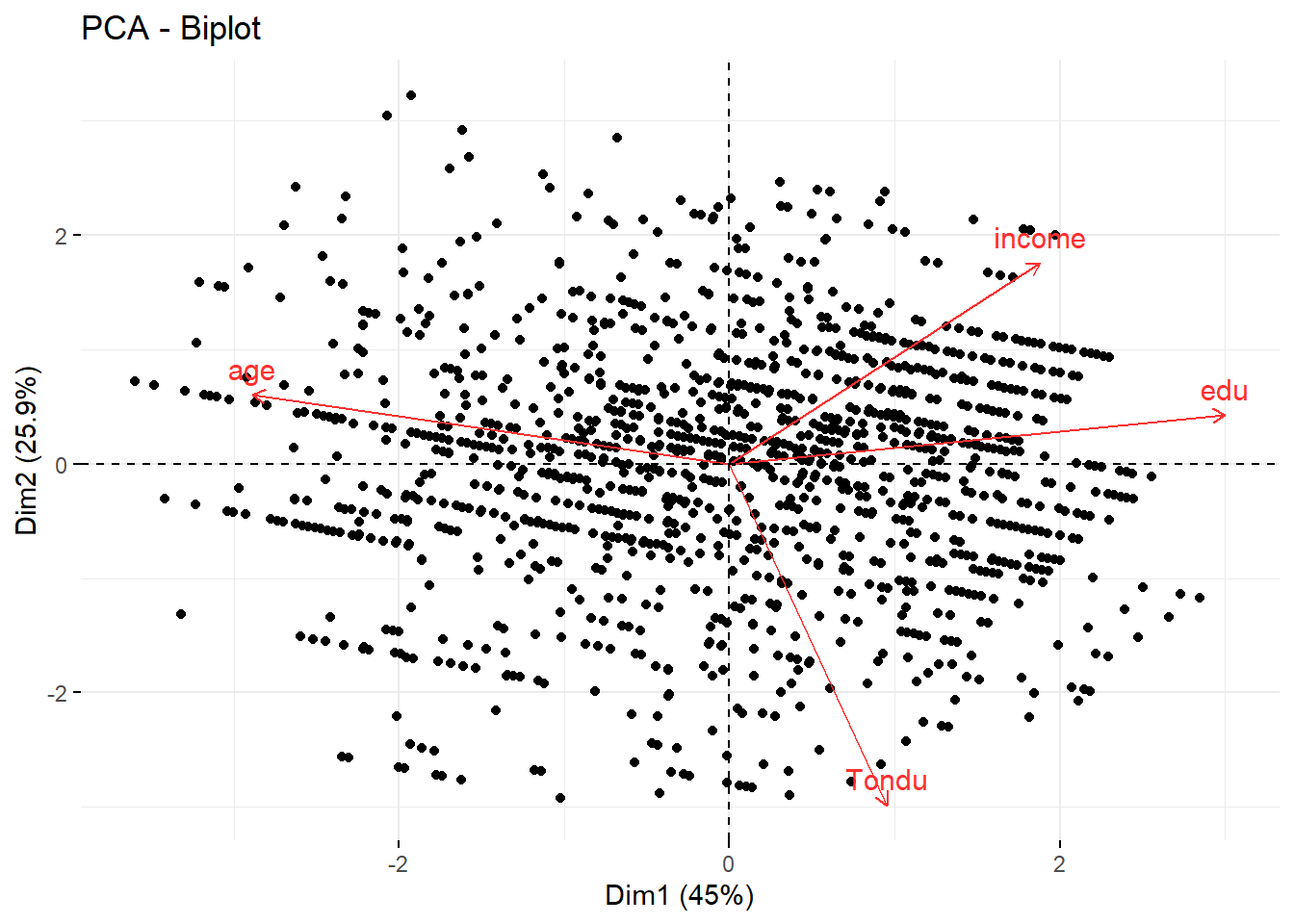
Below is a principal component analysis on age, education and income.
I thought about visualizing a 3-dimensional PCA to see if categorization without factoring in Tondu arose, but found that relying on only 3 variables (age, education, income) made increasing components unnecessary: the total explained variance was already plenty high and the resulting visualization was just a slop. Technically addressing more parts of the Tondu polling data was outside the scope of the initial assignment, but perhaps I’ll readdress it with more variables another time, as well as reintroducing Tondu into the PCA on its 1:5 scale. That’s all for now.